特化型人工知能(AI)は神ではないが多くの人達はそのことを直感的に理解できない
ChatGPTやStableDiffusion,Midjourneyのような一般に使いやすい機械学習系のアプリケーションを使ってみた人たちの反応を見ていて、気になる部分があった。
(ChatGPT(文章生成系)、Diffusion,Midjourney(画像生成系))
まるで、彼らの多くはそれらのアプリケーションが自発的に「考え」、考えた結果を「生成」しているように捉えているように見えるのだ。
自分からすると、ChatGPT等はネット上に転がっている関連ワードを一瞬で集めてくれるお手軽な収集装置にしか見えないのだが、(※制度の良い検索ブラウザのようなもの)どうも、多くの人はそうは捉えていないらしい。
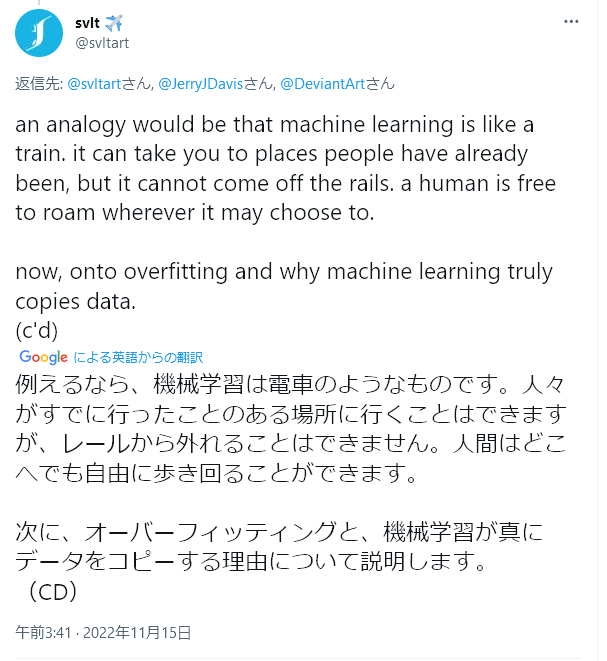
実は勉強しているようであまり勉強しているわけではないので、プロセスについて具体的なことは述べるのを控えていたが、とはいえ、微分方程式モデルの数値研究をしていたものとして、直観的にどういう現象なのかわかる部分はある。
つまり、それらのアプリケーションは内部処理として「考えて」いるわけではなく、集めた情報の値を内部の数値モデルに当てはめてその結果を出力しているだけであるということだ。
こちらの人のざっくりとした画像モデルの解説に興味深いことが書いてあった。
https://twitter.com/svltart/status/1591187799902130176?s=20&t=r6sGsdZpSU7oHrDT57rusA
this is how dreamup is being developed. it adds training on non-opt-out artwork on top of the stability diffusion model, which is ALREADY trained using unethically sourced data. they CANT UNLEARN those parts.
— svlt ✈️ (@svltart) 2022年11月11日
this whole discussion is not in good faith unless they address this pic.twitter.com/KnQZerCIol


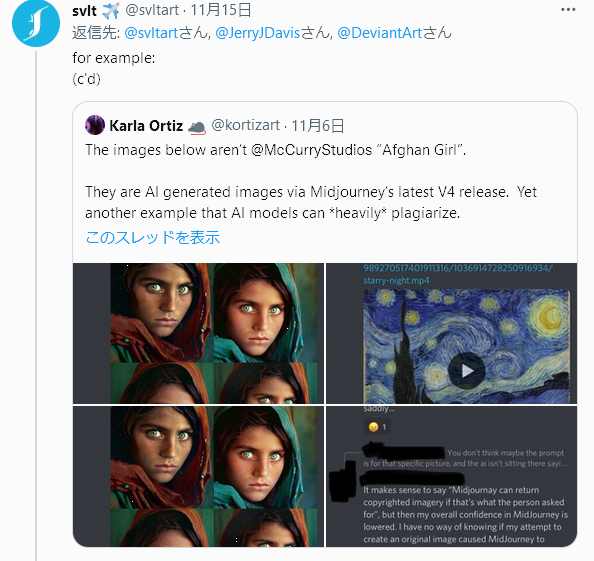
最後の画像の左はアフガンガールに類似して出力されてしまったAI生成画像である。

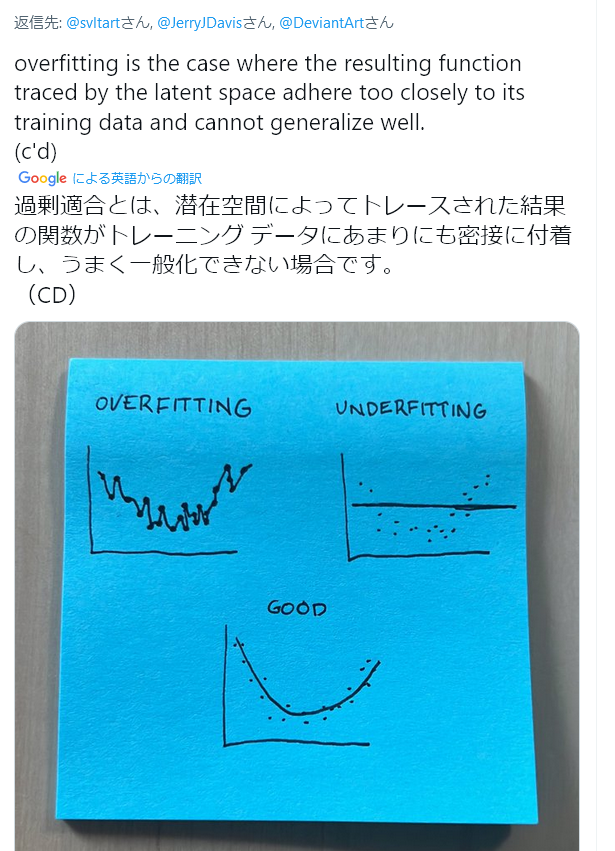
ここでの解説を見るに、現在の機械学習画像生成アプリケーションには学習元の絵に類似した点の部分が出力されやすいという本質的な特徴がある。
かなりざっくりといえば、「参照元にした画像そっくりになりやすい」ということだ。
三次元的な「構造」を本質的に理解しているわけではない、このタイプのピクセルベースの二次元画像抽出アプリケーションがどのようにして違和感の少ない画像を生成しているのかが不思議だったが、この説明が正しいとすれば、ある程度納得がいく。
たとえば、3DCGソフトの人型キャラクターが、スタジオでスキャンした人間の動きを違和感なく転写して再現するのは、あれは骨の配置や回転角などの人体の解剖学的な情報をあらかじめ人間のデザイナー(リガ―)がそれらの3次元的な特徴点の集合である3Dモデルに紐づけて指定しているからである。
そうした前準備がない無作為の画像を大量に読み込むだけでそれらしい画像を再構成できてしまう理由が謎だったが、その理由は、なんのことはない、元の特徴点に近い画像が抽出されやすくなっているだけの仕組みだったらしい。
また、生成画像の良し悪しを判断し、最後に選ぶのが人間である以上、選ぶ側の人間は自然に見える、より元の学習元の画像に近い特徴を持った画像を選んでしまいがち、という現象もありそうだなと思った。
どうやら、AIが独自に合成した絵柄というよりは、絵の制作者名ロンダリングに近い仕組みであるという風に見えている。いまのところ。
https://https://twitter.com/svltart/status/1591187799902130176?s=20&t=r6sGsdZpSU7oHrDT57rusAtwitter.com/svltart/status/1591187799902130176?s=20&t=r6sGsdZpSU7oHrDT57rusA